Reinforcement learning
Reinforcement learning (RL) is an area of machine learning inspired by behavioral psychology. The concept of reinforcement learning is based on cumulative rewards or penalties for the actions that are taken by an agent in a dynamic environment. Think about a young dog growing up. The dog is the agent in an environment that is our home. When we want the dog to sit, we might simply say, “Sit.” The dog doesn’t understand English, so we might nudge it by lightly pushing down on its back. After the dog sits, we pet it or give it a treat - this is a welcomed reward. We need to repeat this many times, but after some time, we have positively reinforced the idea of sitting for the dog. The trigger in the environment is saying “Sit”; the behavior learned is sitting; and the reward is pets or treats.
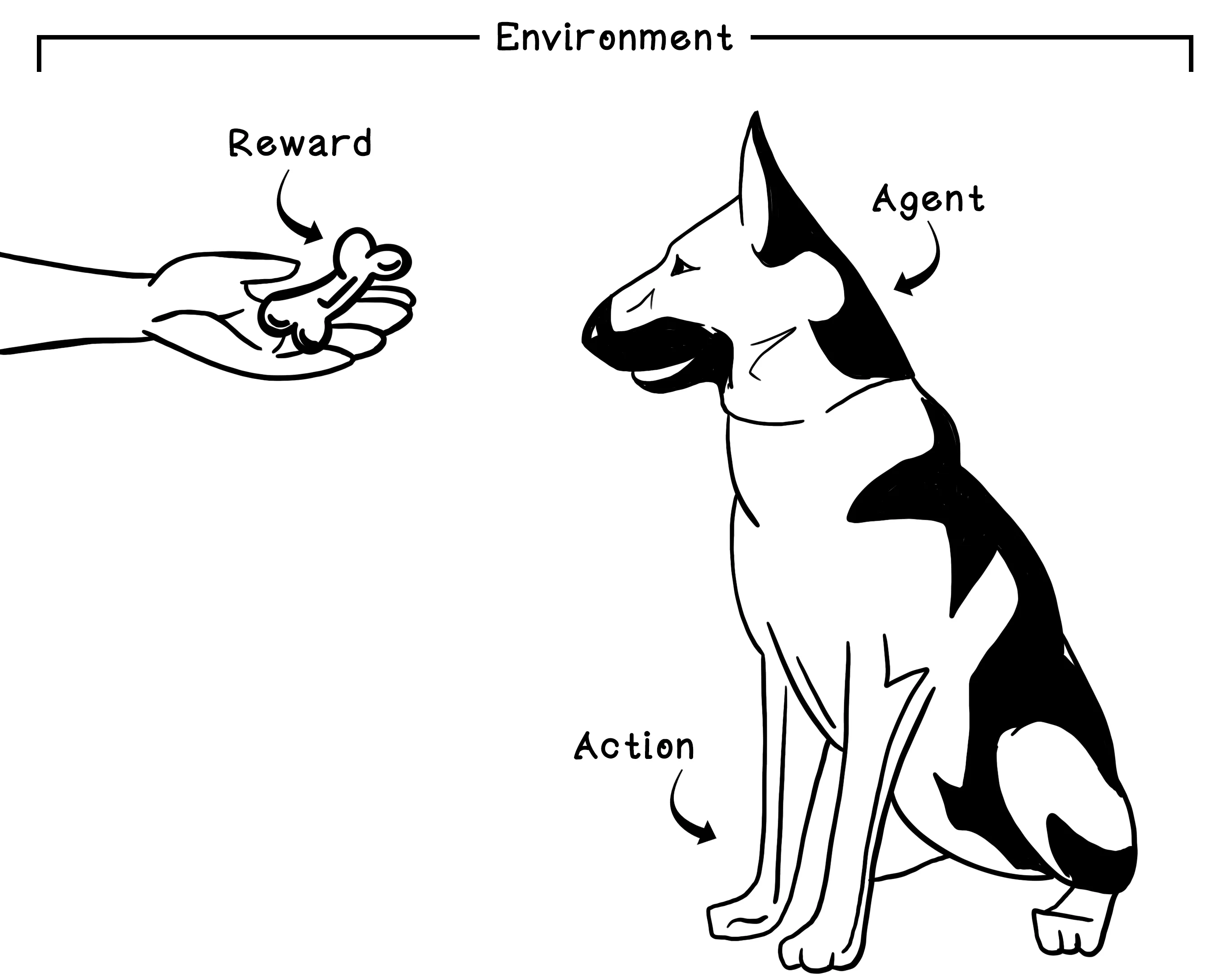
Like other machine learning algorithms, a reinforcement learning model needs to be trained before it can be used. The training phase centers on exploring the environment and receiving feedback, given specific actions performed in specific circumstances or states. The life cycle of training a reinforcement learning model is based on the Markov Decision Process, which provides a mathematical framework for modeling decisions. By quantifying decisions made and their outcomes, we can train a model to learn what actions toward a goal are most favorable.
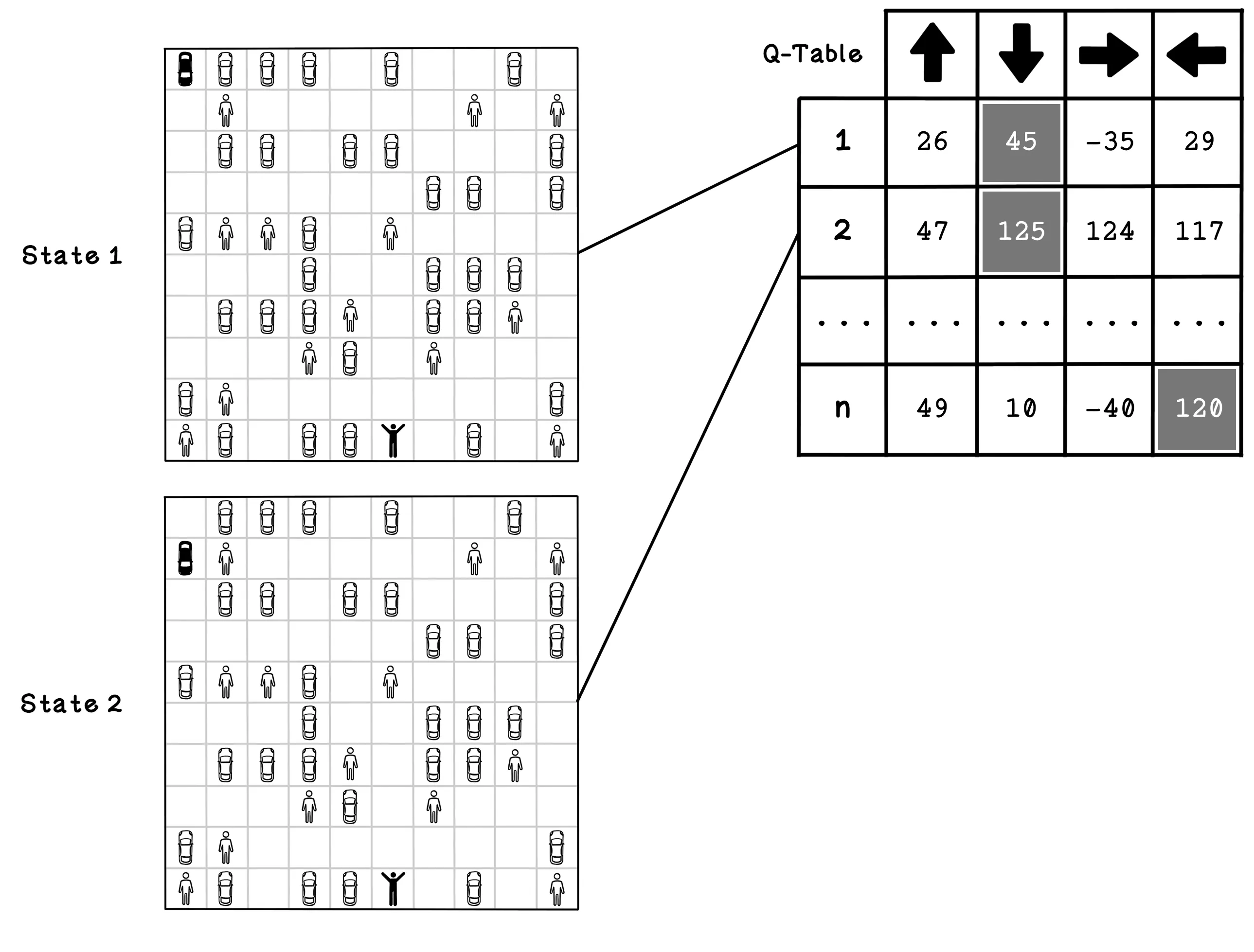
Imagine a parking-lot scenario containing several other cars and pedestrians. The starting position of the self-driving car and the location of its owner are represented as black figures. In this example, the self-driving car that applies actions to the environment is known as the agent. The self-driving car, or agent, can take several actions in the environment. In this simple example, the actions are moving north, south, east, and west. Choosing an action results in the agent moving one block in that direction. The agent can’t move diagonally.
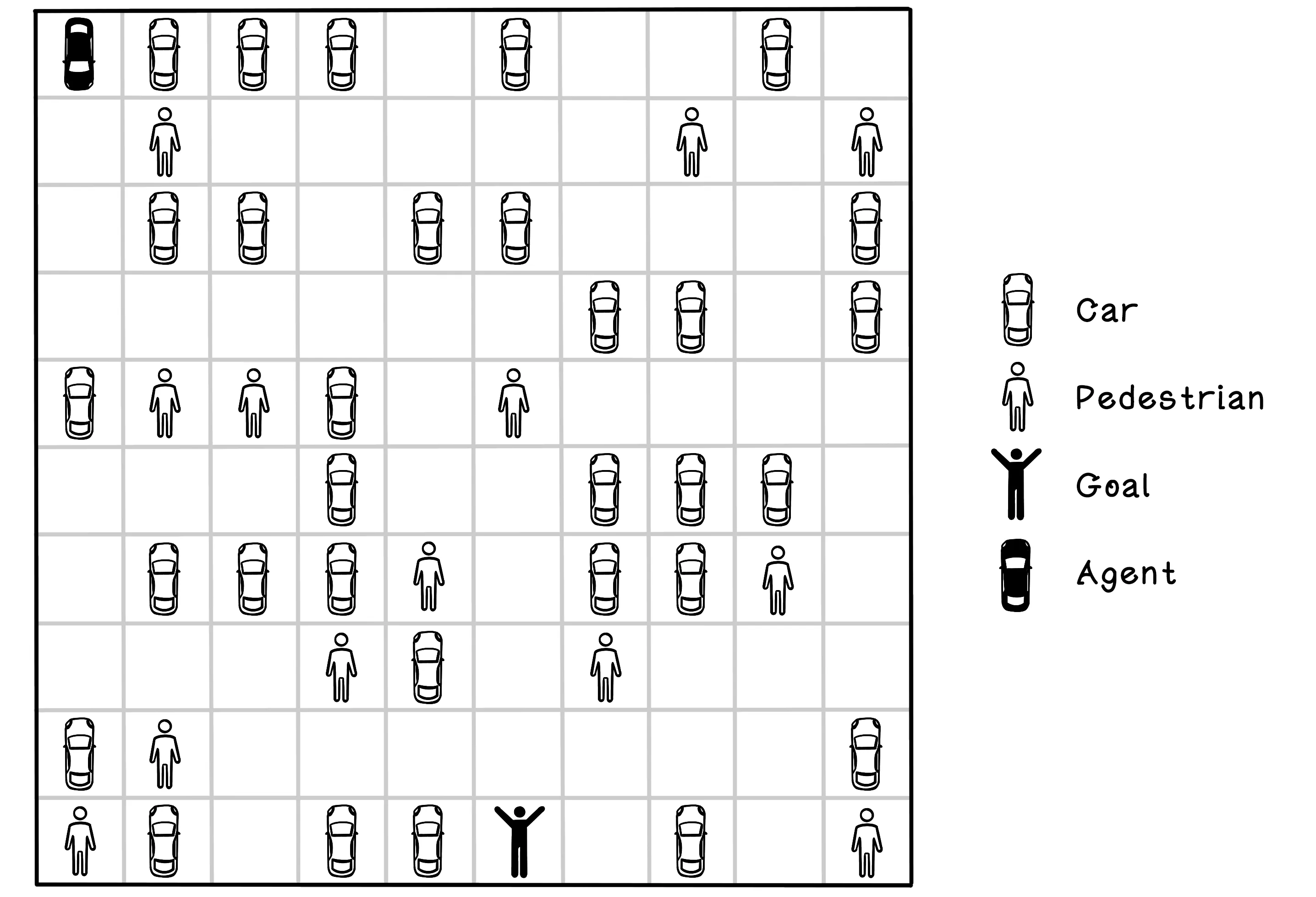
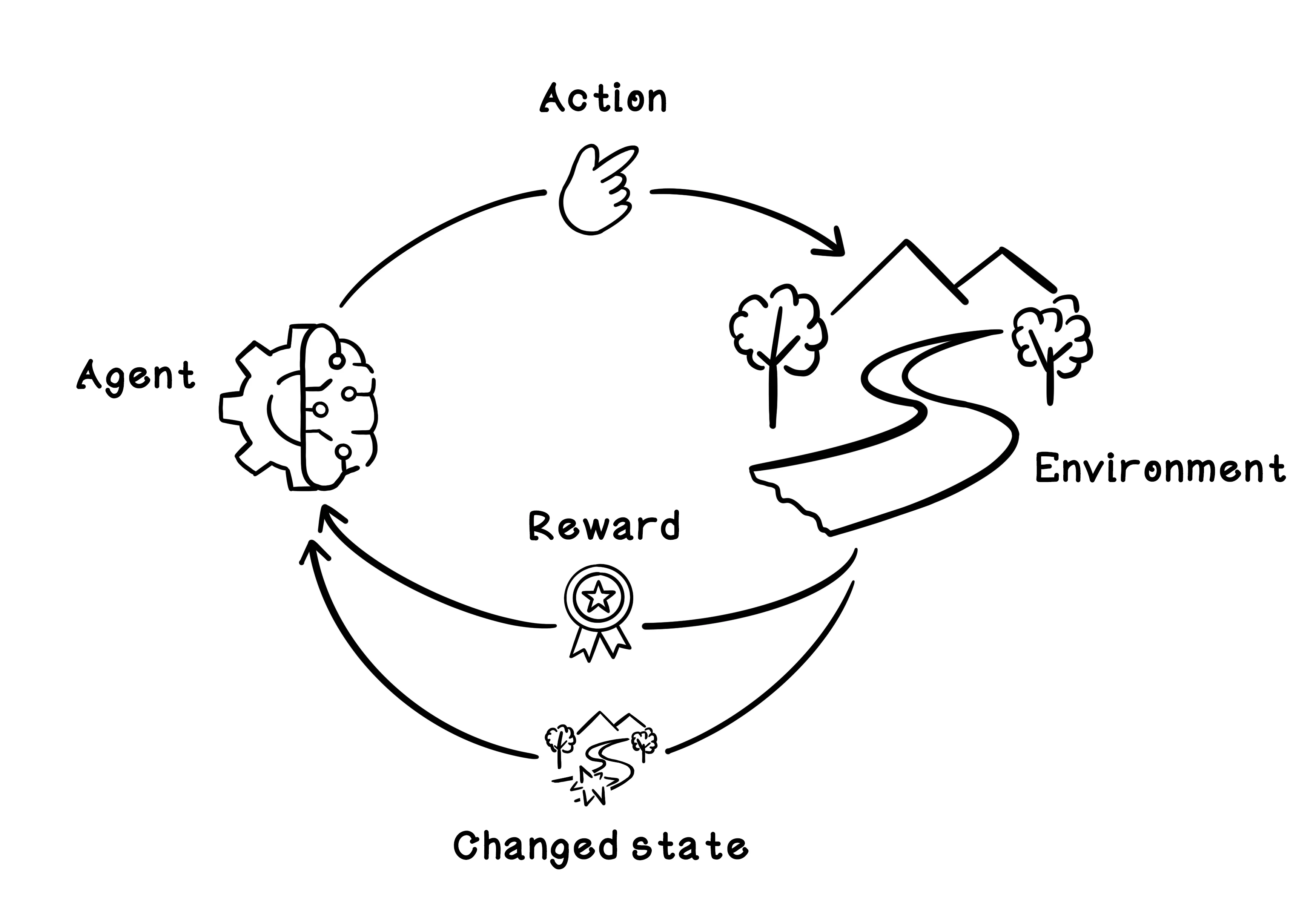
The simulator needs to model the environment, the actions of the agent, and the rewards received after each action. A reinforcement learning algorithm will use the simulator to learn through practice by taking actions in the simulated environment and measuring the outcome. The simulator should provide the following functionality and information at minimum:
- Initialize the environment — This function involves resetting the environment, including the agent, to the starting state. Get the current state of the environment—This function should provide the current state of the environment, which will change after each action is performed.
- Apply an action to the environment—This function involves having the agent apply an action to the environment. The environment is affected by the action, which may result in a reward.
- Calculate the reward of the action—This function is related to applying the action to the environment. The reward for the action and effect on the environment need to be calculated.
- Determine whether the goal is achieved—This function determines whether the agent has achieved the goal. The goal can also sometimes be represented as completed. In an environment in which the goal cannot be achieved, the simulator needs to signal completion when it deems necessary.
Reinforcement Learning with Q-Learning
Q-learning is an approach in reinforcement learning that uses the states and actions in an environment to model a table that contains information describing favorable actions based on specific states. Q-learning is a model-free approach (meaning it doesn’t need to know the physics of the world beforehand). It learns to estimate the quality of taking actions in specific states.
Reinforcement learning with Q-learning employs a reward table called a Q-table. Think of a Q-table as a scorecard. The rows are the possible states, and the columns are the possible actions. Each cell contains a Q-Value (Quality Value). The table doesn’t explicitly store “the best action”; rather, it stores a score for every possible action. To find the best action, the agent looks at the row for its current state and picks the action with the highest Q-Value.
The point of a Q-table is to describe which actions are most favorable for the agent as it seeks a goal. The values that represent favorable actions are learned through simulating the possible actions in the environment and learning from the outcome and change in state.
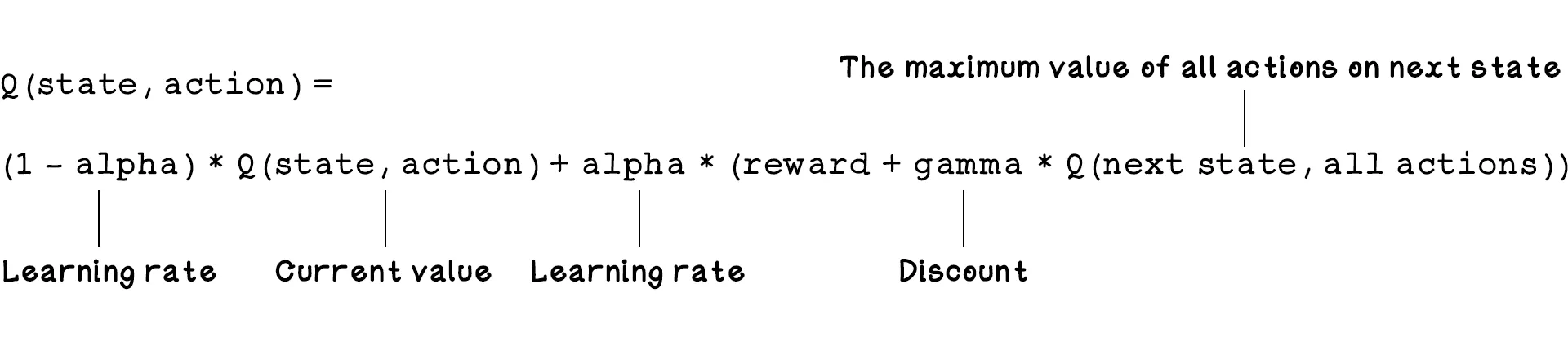
It’s worth noting that the agent has a chance of choosing a random action or an action from the Q-table. The Q represents the function that provides the reward, or quality, of an action in an environment. The example below shows a trained Q-table and two possible states that may be represented by the action values for each state. These states are relevant to the problem we’re solving; another problem might allow the agent to move diagonally as well. Note that the number of states differs based on the environment and that new states can be added as they are discovered. In state 1, the agent is in the top-left corner, and in state 2, the agent is in the position below its previous state. The Q-table encodes the estimated value of taking an action in a state. Once the table is fully trained (converged), the action with the largest number is considered the most beneficial. Note that at the start of training, these numbers are just random guesses; they only become accurate “best actions” after many trials. Soon, we will see how they’re calculated.
Rewards define behavior
One of the most important ideas in reinforcement learning is that the reward function quietly defines what the agent cares about. If we reward speed too heavily, the agent may act recklessly. If we punish collisions but give no incentive to finish quickly, the agent may learn to move too cautiously. Designing the reward is therefore part of designing the intelligence.
Start the simulation and watch how messy the agent’s behavior is at first. Early on, the agent explores, makes poor moves, and often fails. Over time, the reward chart and success metrics reveal whether it is actually improving. Then change the exploration, learning rate, and discount rate one at a time so you can see what each control does. Higher exploration makes the agent more willing to try new actions, the learning rate changes how quickly it updates from experience, and the discount rate changes how much it values long-term reward versus immediate payoff.
The easiest way to understand Q-learning here is to treat the grid as the world, the metrics as the report card, and the reward chart as the learning history. You are not just watching a car move around a map; you are watching a policy slowly emerge from repeated trial and error.
This parking-lot toy is intentionally small enough for a Q-table to work. In richer environments, the number of states can explode, which is why larger reinforcement learning systems often need function approximation and neural networks.
Grokking AI Algorithms
How AI solves complex problems
A practical, visual guide to the algorithms that power search, machine learning, neural networks, LLMs, and generative AI.

Reinforcement Learning Frequently Asked Questions (FAQ)
What is reinforcement learning?
Reinforcement learning is a way for an agent to learn through trial and error. It takes actions, receives rewards or penalties, and gradually learns which behaviors lead to better long-term outcomes.
How is reinforcement learning different from supervised learning?
In supervised learning, the model learns from examples with correct answers already provided. In reinforcement learning, the agent must discover good behavior by interacting with an environment and receiving feedback over time.
What is Q-learning?
Q-learning is a reinforcement learning method that estimates how valuable each action is in a given state. Those learned values help the agent choose actions that are more likely to lead to success.
What is a state in reinforcement learning?
A state is the current situation the agent is in. In the gridworld demo, that includes the agent's position and the environment it must navigate.
What is an action in reinforcement learning?
An action is a move or decision the agent can take from the current state. Learning depends on understanding how different actions change future rewards.
What is a reward in reinforcement learning?
A reward is the feedback signal telling the agent how good or bad a recent outcome was. The agent uses those signals to improve its decisions over time.
Why do rewards matter so much in reinforcement learning?
Rewards define what the agent is actually optimizing for. If the rewards are poorly designed, the system may learn behavior that technically earns points but does not match the outcome you really wanted.
What is epsilon-greedy exploration?
Epsilon-greedy exploration means the agent usually picks the best-known action but occasionally tries something else at random. That balance helps it learn without getting stuck too early.
What is the discount factor in reinforcement learning?
The discount factor controls how much the agent values future rewards compared with immediate ones. It helps determine whether the agent behaves short-term or long-term.
What does the gridworld simulation help explain?
It makes rewards, penalties, exploration, and learned behavior visible in a simple environment. You can watch the agent gradually improve from repeated experience.
Why is reinforcement learning useful in AI?
It is useful when correct action sequences are not obvious in advance and must be learned through interaction. Robotics, games, control systems, and adaptive decision-making are common examples.